综述
传统的HDFS
Hadoop分布式存储系统主要组成部分包括Namenode、Datanode 、Adapter、zookeeper,存储访问方式大体上分为两种,客户端访问和FsShell两种方式。
-
Namenode:管理文件系统的命名空间。它维护着文件系统树及整棵树内所有的文件和目录。同时还记录着每个文件中各个block所对应dn(Datandoe)信息,即通过访问nn(Namenode)我们就可以获得你所需要的文件所存储的具体位置。
-
Datanode:文件block实际存储的位置。每个文件被分为若干个block,文件存储的粒度为block,每个block备分散存储于不同的三个dn。
改进的HDFS(PETA)
HDFS中单namenode 架构无法满足海量文件存储及大吞吐量的需求,因此将单点的namenode 拆分成由Namespace 和多个FMS 组成的架构。
-
Namespace:支持对文件系统中的目录、文件做类似文件系统的增删改查等基本操作。只进行目录树管理,记录文件名、目录的修改时间及访问时间、目录的副本数及目录的空间用量、目录的权限、目录的孩子列表、文件objectID 等信息;
-
FMS:维护文件分块及其副本信息,记录文件名、父亲目录、修改时间、访问时间、副本数、目录的孩子信息、目录的空间用量、文件的分块信息、文件的预计分块大小、文件的源dn 等信息;
整体架构图如下:
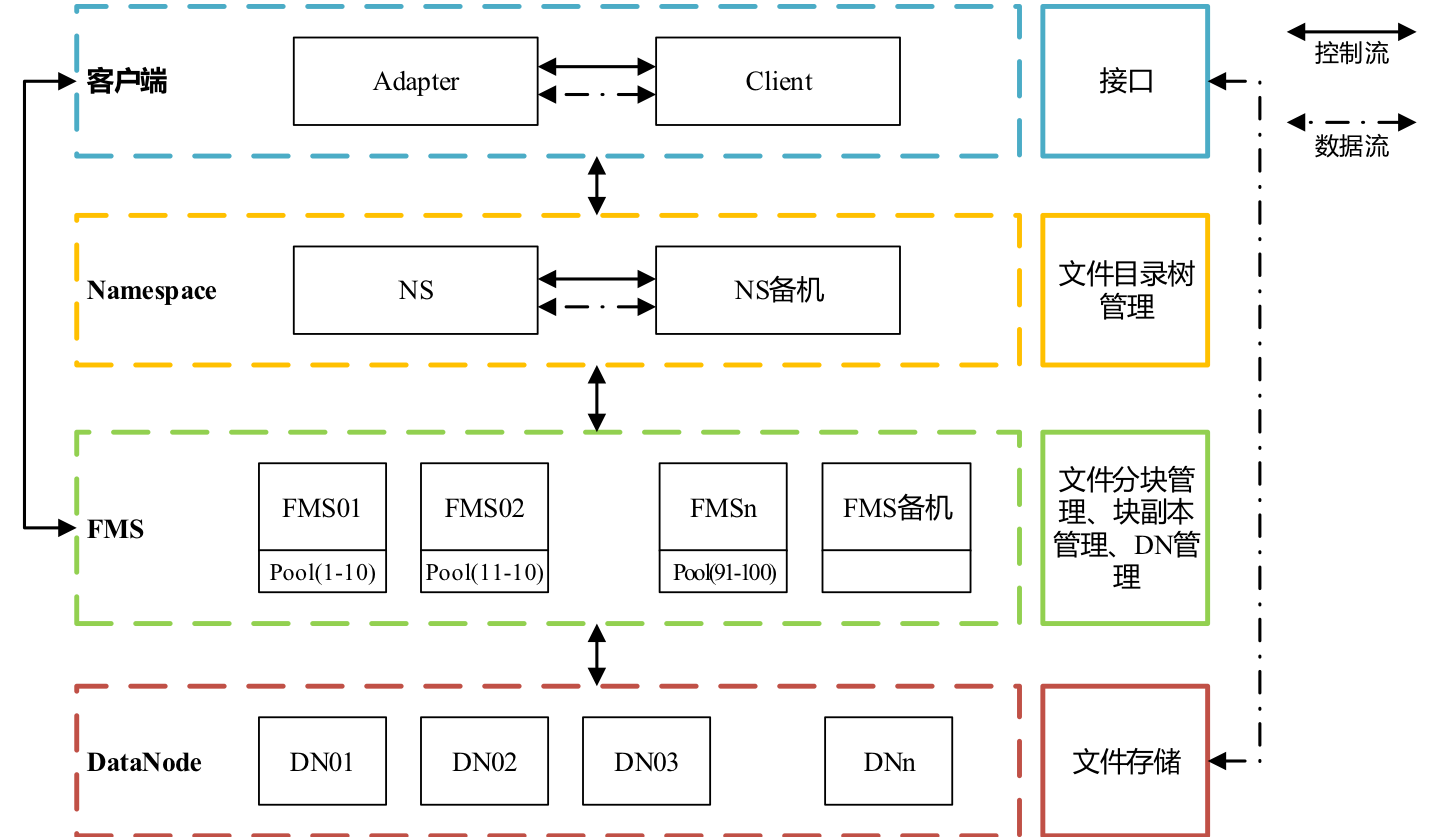
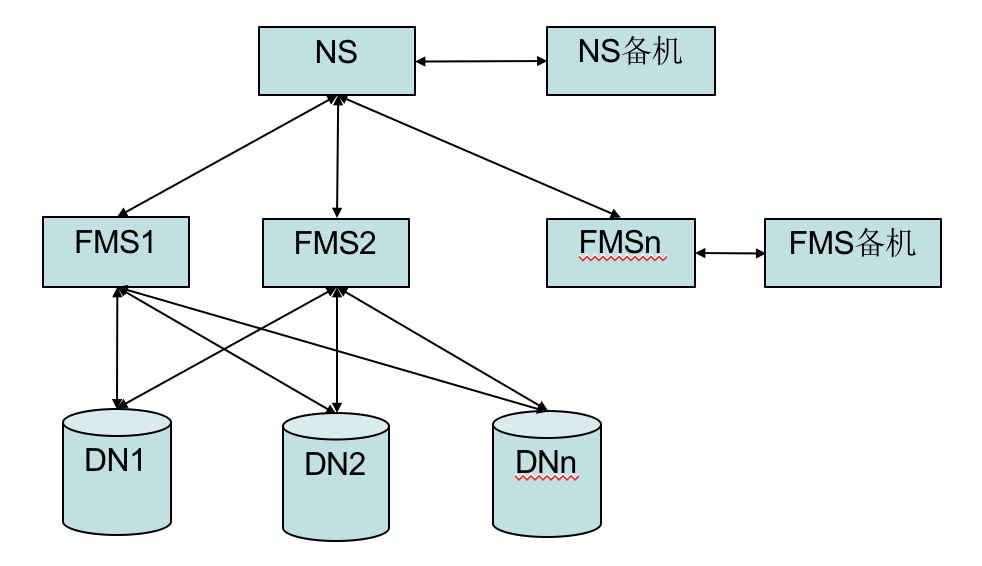
Namspace只负责命名空间管理,文件节点只记录文件的基本信息;FMS管理文件对象的全部信息并独立进行文件块副本维护并且 多个FMS共享底层DataNode。
PETA中的元数据
元数据类型
元数据按存储方式可分为内存中的元数据和磁盘上的元数据。
- Namespace:其元数据主要包括内存中的目录树、inode、fsimage、edits。
- FMS:与Namespace相同,其还有blocksmap即文件和block的对应关系以及block与dn的对应关系。
其中:
- 内存中的元数据:目录树、inode、blocksmap
- 磁盘上的元数据:fsimage、edits
NS上的元数据
元数据关系图如下:
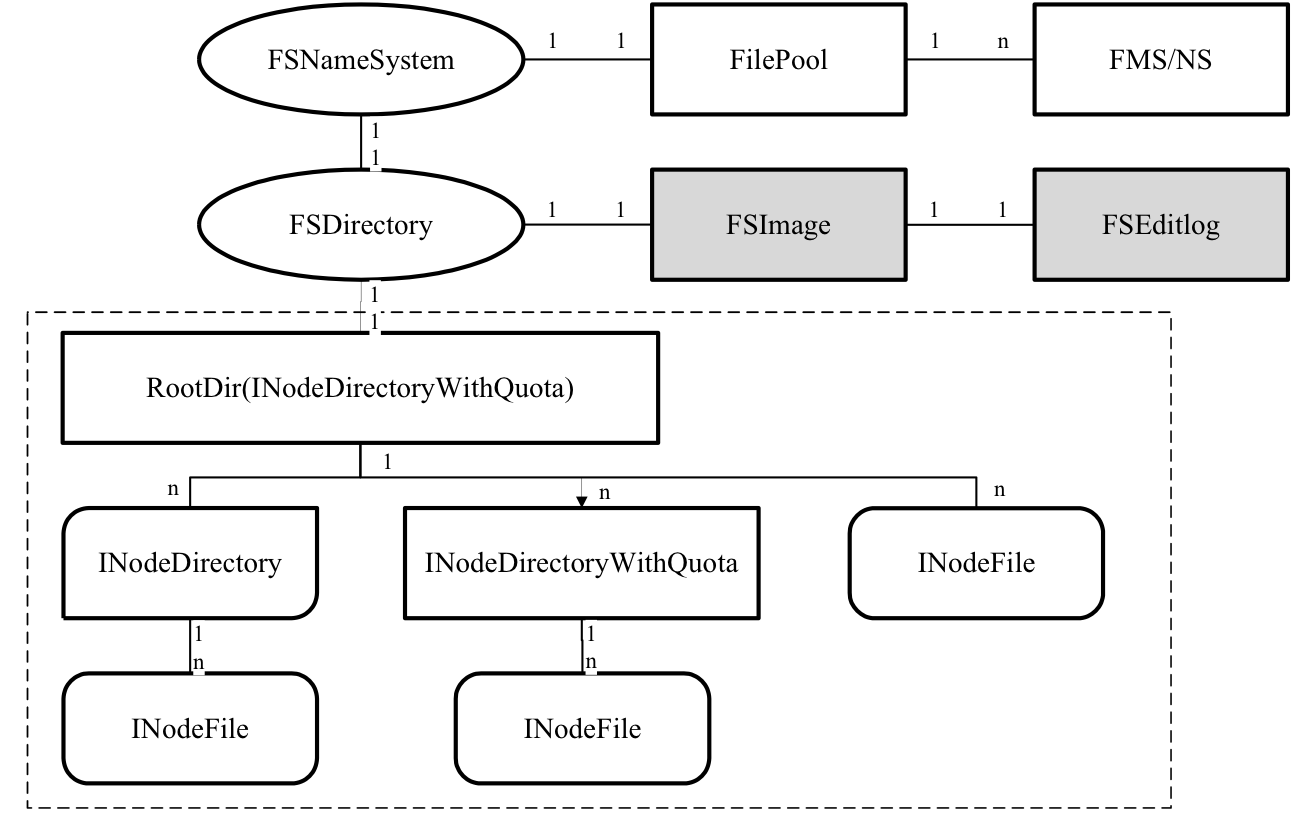
1.FSDirectory
其用于维护目录树的状态,目录树存储有整个集群所存储的全部文件,
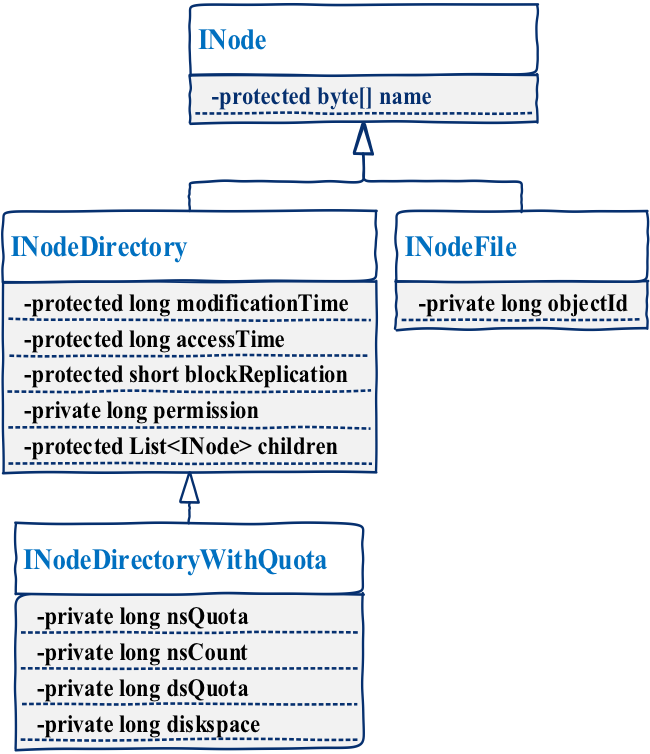
2.inode
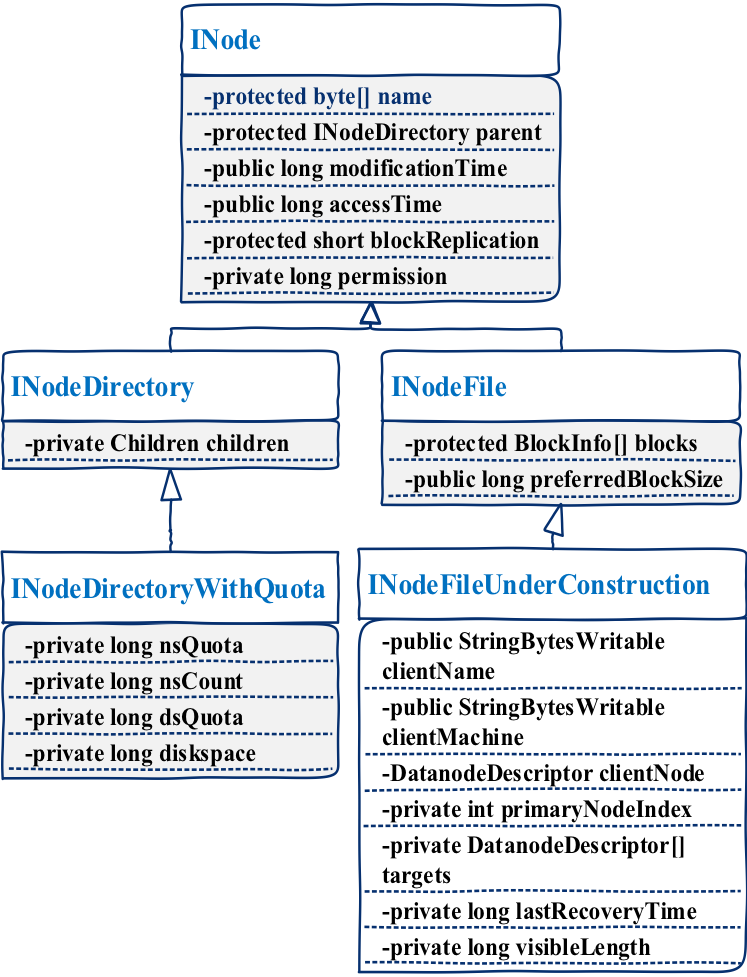
每个inode对应一个文件,其为一个抽象类,被INodeDirectory和INodeFile两类继承,INodeDirectoryWithQuota继承INodeDirectory,增加了存储容量限制等相关部分。
其中,INodeDirectory为目录对象,可以有多个孩子。INodeFile为文件对象,文件目录树的叶子节点,用于存储文件的基本信息,如文件的权限,文件名,以及objectid(唯一的)。不同类型的继承关系如下图:
其objectID的格式:

- poolID:表示文件的相关信息存储在哪个fms上。
- zkkey:表示某个ns(多ns的集群使用)
- 自增文件序号:每新添加一个文件就会自增,用来表示文件的唯一性。
3.fsimage
是内存元数据到硬盘的一个checkpoint,存储当前内存中文件目录树的状态。当出现故障时可用于恢复元数据。其文件头包含:imgVersion, namespaceID, numFiles, genStamp等信息。
4.edits(redo日志)
用于记录对文件目录树的修改操作,当用户修改目录树时,会首先进行用户的op,之后会记录该操作到磁盘edit文件。
实现是通过双buffer,bufcurrent和bufready,当前的op会记录到bufcurrent,当去刷盘操作时,会讲bufcurrent中的数据写入bufready,后续操作将有bufready写入磁盘,而bufcurrent可以接收新的数据。
##(补个写日志的示意图)。
FMS上的元数据
FMS上与ns上原数据的不同在于FMS上会存储与block和dn相关的信息。
1.inode
与ns不同的是,f其inode的子类INodeFile中增加了文件对应的全部block信息(包块有哪些块,以及每个块所对应的dn),同时新增了一个文件类型INodeFileUnderconstruction,其继承于INodeFile,这个文件类型表示正在创建的文件,其中有这个文件当前存储最后一个block的dn,当文件完成创建时会转换成INodeFile类型。不同类型的继承关系如下图:
其blockID的格式:

2.blocksmap
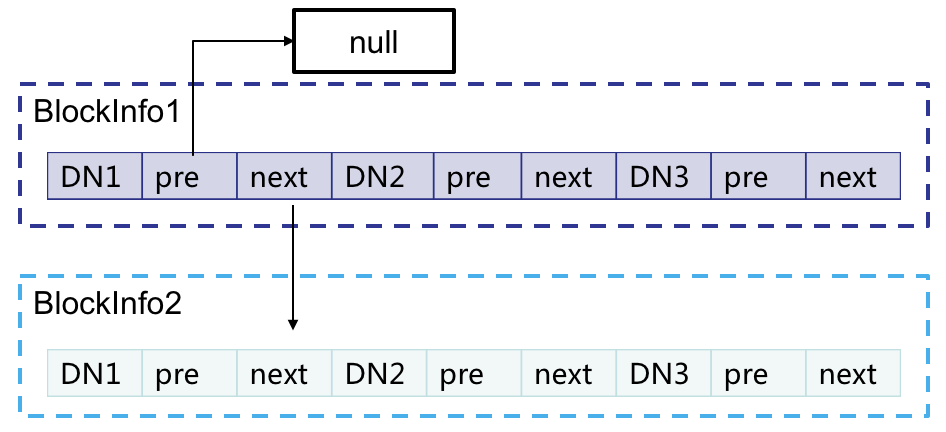
这个结构是FMS上独有的,用于记录文件->block以及block->dn之间的对应关系。在查找某个文件的dn时,可以通过INodeFIle中存有的block,去查找map,从而找到对应block的blockinfo,而blockinfo中存有对应的dn信息。blockInfo是BlocksMap的内部类:其定义了一个Object类型的triplets数组。其中定义了一些方法,比如查询dn操作,添加dn操作,以及在链表中的插入删除操作等。其中triple结构如下:
3.datanodeMap
此结构中保存着dn的机器ip以及对应dn的DatanodeDescriptor,DatanodeDescriptor中包含有这个dn的使用容量、可用容量、上一次更新的时间、存储在这个dn上的blockList的链表头(从而能找到这个dn上的所有block信息),还有这个dn的待复制、待回收、待recover的block队列。这些信息会在dn和fms心跳通信时维护更新(这个之后会介绍)。
文件读写的流程
在本文中,将结合元数据介绍下文件读写的大体流程,具体的读写流程在之后会详细介绍。
(一)读流程
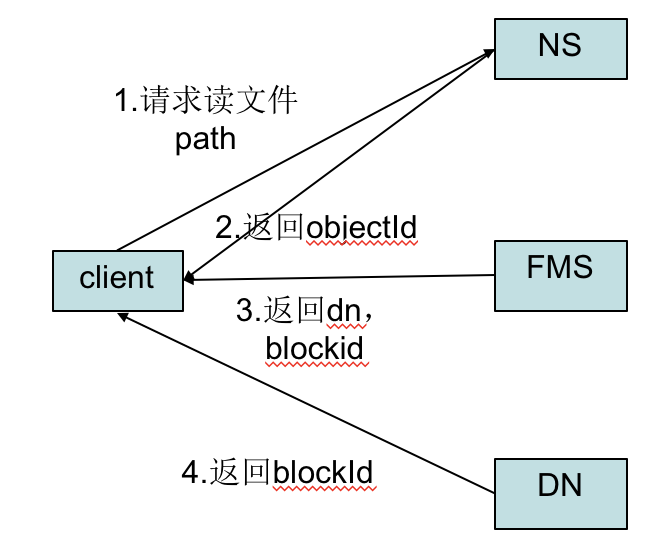
- 初始化FileSystem,然后客户端(client)用FileSystem的open()函数打开文件:
- 向NS发送open请求,NS通过path找到对应的inode并返回ObjectID给客户端。
- 客户端通过ObjectID.poolID找到对应的fms,并发送open请求,fms返回文件的数据块信息,对于每一个数据块,fms返回保存数据块的数据节点的地址。
-
FileSystem返回FSDataInputStream给客户端,用来读取数据,客户端调用stream的read()函数开始读取数据。
-
DFSInputStream连接保存此文件第一个数据块的最近的数据节点,data从数据节点读到客户端(client)
-
当此数据块读取完毕时,DFSInputStream关闭和此数据节点的连接,然后连接此文件下一个数据块的最近的数据节点。
-
当客户端读取完毕数据的时候,调用FSDataInputStream的close函数。
-
在读取数据的过程中,如果客户端在与数据节点通信出现错误,则尝试连接包含此数据块的下一个数据节点。
- 失败的数据节点将被记录,以后不再连接。
(二)写流程
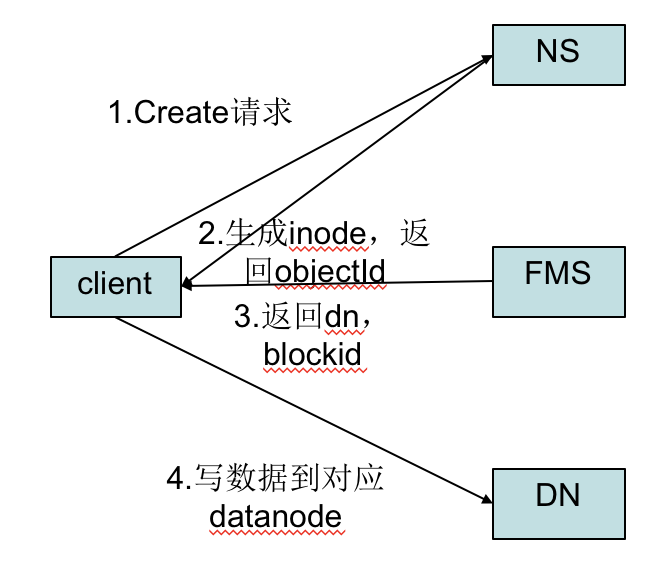
- 初始化FileSystem,客户端调用create()来创建文件:
- 首先向NameSpace发送create请求,此时会在NameSpace上生成inode,并返回这个inode的ObjectID。
- 然后客户端通过ObjectID.poolID找到对应的fms,之后向fms发送create请求,fms会创建一个inode,并创建这个inode的数据流DFSOutputStream。
-
FileSystem返回DFSOutputStream,客户端用于写数据,客户端开始写入数据。
-
DFSOutputStream将数据分成块,写入data queue。data queue由Data Streamer读取,并通知元数据节点分配数据节点,用来存储数据块(每块默认复制3块)。分配的数据节点放在一个pipeline里。Data Streamer将数据块写入pipeline中的第一个数据节点。第一个数据节点将数据块发送给第二个数据节点。第二个数据节点将数据发送给第三个数据节点。
-
DFSOutputStream为发出去的数据块保存了ack queue,等待pipeline中的数据节点告知数据已经写入成功。
-
当客户端结束写入数据,则调用stream的close函数。此操作将所有的数据块写入pipeline中的数据节点,并等待ack queue返回成功。最后通知元数据节点写入完毕。
- 如果数据节点在写入的过程中失败,关闭pipeline,将ack queue中的数据块放入data queue的开始,当前的数据块在已经写入的数据节点中被元数据节点赋予新的标示,则错误节点重启后能够察觉其数据块是过时的,会被删除。失败的数据节点从pipeline中移除,另外的数据块则写入pipeline中的另外两个数据节点。元数据节点则被通知此数据块是复制块数不足,将来会再创建第三份备份。